Problem Statement:
How do movie budgets correlate with their gross revenue across various platforms (Disney, Netflix, Hulu, Max) and categories (Top 250 Movies, Most Popular Movies)? Does a higher budget lead to better financial performance? How do these relationships vary by genre and platform?
Goal:
- Analyze budgetvs gross revenue across movies in different streaming categories (Top 250 Movies, Most Popular Movies, Netflix Movies, etc.).
- Explore the impact of budget on profitability by genre.
Overview:
The goal of this project was to extract, organize, and visualize movie and TV show data from the IMDb website and organize it into structured databases, clean and transform the data, and then visualize key insights using Power BI. Using Python’s BeautifulSoup for web scraping and SQL Server for data storage, I extracted details from IMDb’s Top 250 Movies, Most Popular Movies, Top 250 TV Shows, Most Popular TV Shows and What to watch lists. The project involved the following key steps:
1. Data extraction using Python and BeautifulSoup.
2. Data cleaning and transformation, including handling currency conversions and missing values.
3. Storing the data in SQL Server.
4. Creating interactive dashboards in Power BI for insights.
Data Extraction:
The following tables were created in SQL Server, each containing similar columns like Series Title, Release Date, Certificate, Runtime, IMDb Rating, Genre, Overview, Director, Stars, No. of Votes, BudgetUSD, GrossWorldwideUSD, Poster Link, and Trailer Link:
- Top 250 Movies
- Most Popular Movies
- Top 250 TV Shows
- Most Popular TV Shows
- Disney Movies
- Netflix Movies
- Hulu Movies
- Max Movies
- TV Streaming Movies
The Python code utilized BeautifulSoup to scrape movie and TV show information, including detailed metadata such as ratings, runtime, certificates, and financial information (budget and gross revenue). The extracted data was then stored in SQL Server.
import requests
from bs4 import BeautifulSoup
import json
import pyodbc
import time
import re
- requests: Used to make HTTP requests to websites to retrieve data.
- BeautifulSoup: A web scraping library that parses HTML and XML documents.
- json: To handle JSON data extracted from the website.
- pyodbc: A library for connecting to databases using ODBC, specifically SQL Server in this case.
- time: Used to control execution delays.
- re: Provides regular expression matching operations.
connection = pyodbc.connect('DRIVER={SQL SERVER};'
'SERVER=DESKTOP-LTAP1EA;'
'DATABASE=IMDB;'
'UID=sa;'
'PWD=password ')
cursor = connection.cursor()
Code Snippet: Establishing Database Connection
This establishes a connection to the SQL Server database using the credentials and server information provided. The cursor object allows you to execute SQL queries.
table_creation_queries = [
'''...''', # Multiple queries
]
for query in table_creation_queries:
cursor.execute(query)
connection.commit()
Code Snippet: Creating Tables if Not Exists
I define a list of SQL queries to create tables (Disney_Movies, Netflix_Movies, Hulu_Movies, Max_Movies, and TV_Streaming_Movies) in the database. Each table stores different movie streaming categories, and it checks if the table already exists before creating one using IF NOT EXISTS.
After executing the table creation queries, connection.commit() is called to save the changes in the database.
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36'}
main_url = 'https://www.imdb.com/what-to-watch/?ref_=nv_watch'
response = requests.get(main_url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
- headers: Adds a user-agent header to the request, mimicking a real browser visit.
- main_url: The main IMDb URL you’re scraping.
- get(): Sends an HTTP request to the URL and retrieves its HTML.
- BeautifulSoup: Parses the HTML content of the response.
urls = []
count = 0
for div in div_tag:
a_tag = div.find('a', class_ = 'ipc-lockup-overlay ipc-focusable')
href = a_tag['href'] if a_tag else 'N/A'
full_url = ('https://www.imdb.com'+href)
urls.append(full_url)
print(f'URL: {full_url}')
count+=1
if count == 5:
break
- urls: Collects the full URLs of the top 5 movies.
- count: Ensures only 5 URLs are extracted.
- The script extracts the URL from the <a> tag and appends it to the urls list.
for url in urls:
list_response = requests.get(url, headers=headers)
list_soup = BeautifulSoup(list_response.text, 'html.parser')
json_data_tag = list_soup.find('script', type='application/ld+json')
Code Snippet: Fetching Movie List from URLs
This iterates over the extracted URLs, fetching their content, and looks for JSON data (<script> tag with ld+json) which contains structured movie information.
for movie in movies:
movie_info = movie['item']
title = movie_info.get('name', None)
description = movie_info.get('description', None)
poster = movie_info.get('image', None)
rating = movie_info.get('aggregateRating', {}).get('ratingValue', None)
vote = movie_info.get('aggregateRating', {}).get('ratingCount', None)
certificate = movie_info.get('contentRating', None)
genre = movie_info.get('genre', None)
movie_url = movie_info.get('url', None)
print(f'Fetching details for {title} ({movie_url})...')
Code Snippet: Extracting Movie Details
The extracted JSON data is looped through to get each movie’s basic details such as name, description, poster, rating, etc.
def movie_details(movie_url):
movie_response = requests.get(movie_url, headers=headers)
movie_soup = BeautifulSoup(movie_response.text, 'html.parser')
details = {}
title = movie_soup.find('h1', {'data-testid' : 'hero__pageTitle'})
# More parsing to get title, release_date, certificate, runtime, rating, genre...
return details
Code Snippet: Fetching Detailed Information for Each Movie
The movie_details() function takes a movie URL, scrapes the details page, and extracts the title, release date, runtime, director, and other relevant information.
def process_budget(details):
budget_value = details['budget']
match = re.match(r'([\D]+)\s*([\d,]+)', budget_value)
if match:
currency = match.group(1).strip()
value_str = match.group(2)
details['budget_currency'] = currency
details['budget_value'] = value_str
Code Snippet: Processing Budget Information
This function processes the budget string and separates the currency from the numeric value using regular expressions.
def convert_to_usd(budget_value, budget_currency):
currency_mapping = {
'USD': 1.0000,
'CA$': 0.74,
'¥': 0.0069,
'€': 1.11,
# Other currency mappings...
}
currency_rate = currency_mapping.get(budget_currency, 1.0000)
numeric_value = float(budget_value.replace(',', ''))
return numeric_value * currency_rate, 'USD'
Code Snippet: Converting Budget to USD
This converts the extracted budget into USD based on predefined conversion rates.
def get_table_name(url):
if 'disney' in url:
return 'Disney_Movies'
# More checks for Netflix, Hulu, Max, etc.
else:
raise ValueError("No matching table name found for the URL")
Code Snippet: Determining the Correct Table Name
Based on the URL, this function returns the appropriate table name to insert the movie data into the SQL database.
cursor.execute(f'''
INSERT INTO {table_name}
(SeriesTitle, ReleaseDate, Certificate, Runtime, ImdbRating, Genre, Overview, Director, Stars, NoOfVotes, BudgetUSD, GrossWorldwideUSD, PosterLink, TrailerLink)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
''',
movie_dtl['title'],
# More details...
)
Code Snippet: Inserting Data into SQL Database
Here, the script inserts the extracted movie details into the respective SQL table using parameterized queries. It ensures all the information is saved into the appropriate fields.
cursor.close()
connection.close()
Code Snippet: Closing the Database Connection
Data Cleaning and Transformation:
Special attention was given to fields like Budget, which included currency symbols and values (e.g., CA$, ¥). A function was developed to convert the values into USD, ensuring consistency across the datasets.
Power BI Dashboards
With the data stored in SQL Server, Power BI was used to create interactive dashboards, offering insights into the movies and TV shows. The dashboards include visualizations like bar charts, line charts, and scatter plots for various metrics such as IMDb ratings, budget vs. gross revenue, and genre analysis. Six Power BI dashboards were created to visualize key metrics and trends from the extracted data.
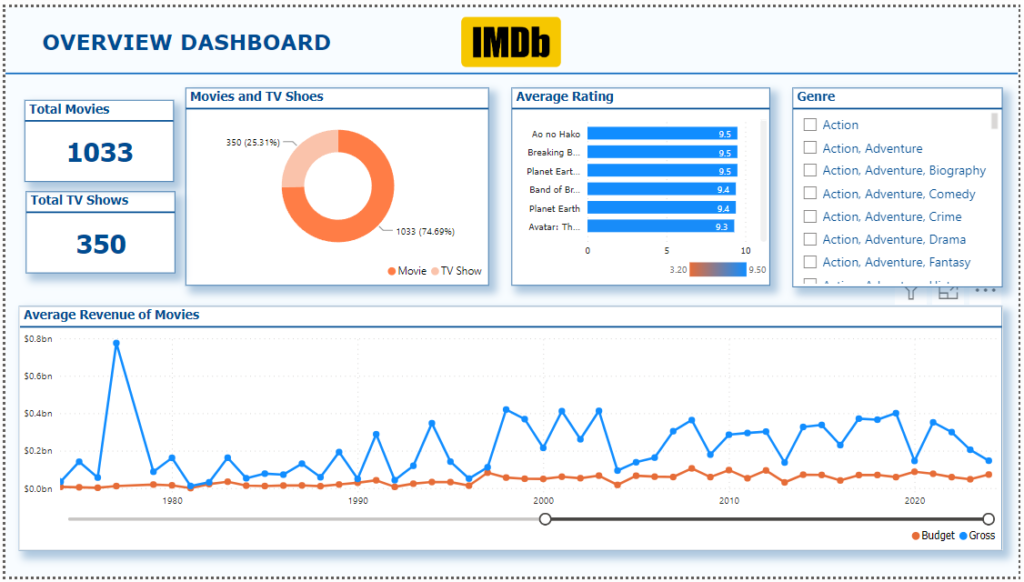
1. Overview Dashboard
- Visuals:
- Card Visual: Displays the total count of movies and TV shows combined.
- Pie Chart: Breaks down the count of movies vs. TV shows, giving a clear percentage of each category.
- Bar Chart: Shows the average IMDb rating across all movies and TV shows, helping you to see how well-rated the content is overall.
- Line Chart: Plots the relationship between Budgetand Gross Revenue, allowing for visual comparison between the amount spent and revenue generated.
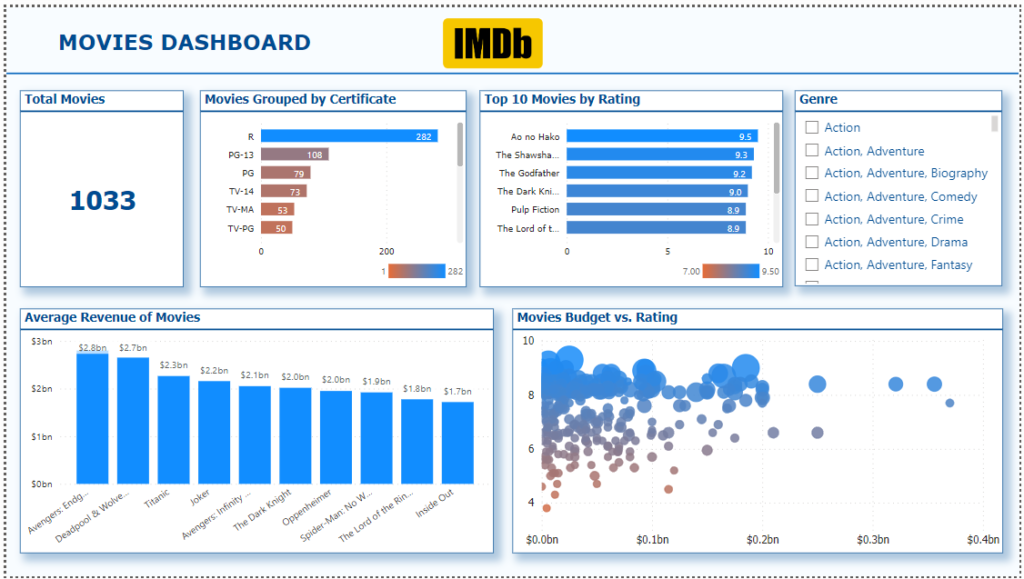
2. Movies Dashboard
- Visuals:
- Card Visual: Shows the total count of all movies in your dataset.
- Bar Chart: Displays the Top 10 movies based on IMDb rating, highlighting the best-rated content.
- Stacked Bar Chart: Groups the movies based on Certificate(like PG-13, R, etc.), providing insight into content rating distribution.
- Bar/Line Chart: Shows movies with the highest gross revenue, giving a sense of financial success.
- Scatter Plot: Plots Budgetagainst IMDb Rating, helping to observe any correlation between the two.
- Average Revenue of Movies: Calculates and displays the average revenue for movies.
- Slicers: Interactive filters are added, allowing users to filter the dashboard by Genre.
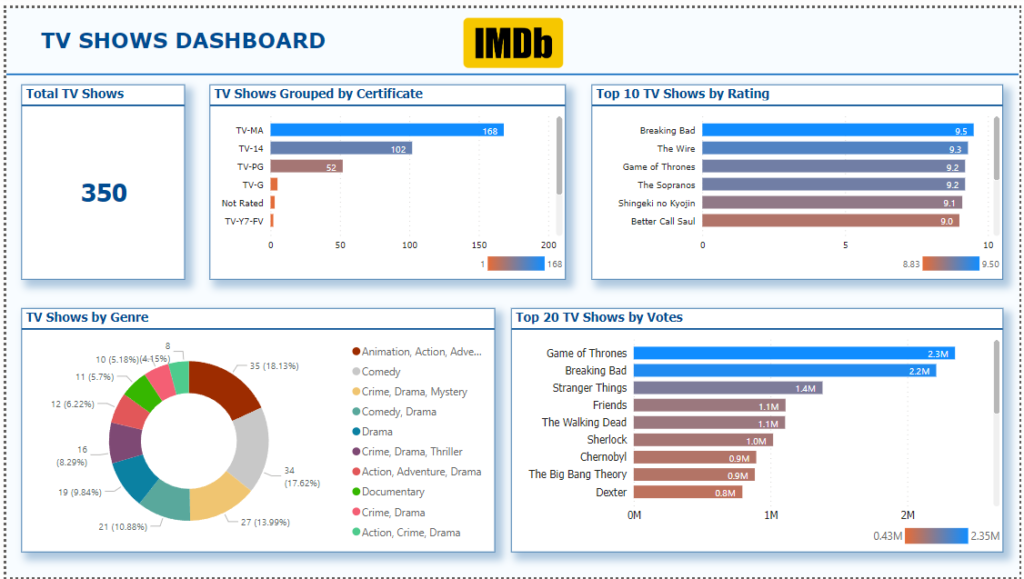
3. TV Shows Dashboard
- Visuals:
- Card Visual: Displays the total count of TV shows in your dataset.
- Bar Chart: Highlights the Top 10 TV shows based on IMDb rating, showcasing the best-rated shows.
- Pie Chart: Visualizes the distribution of TV shows by Genre, helping to see which genres are most common.
- Bar Chart: Displays the Top 20 TV shows by number of votes, showing which shows received the most engagement from viewers.
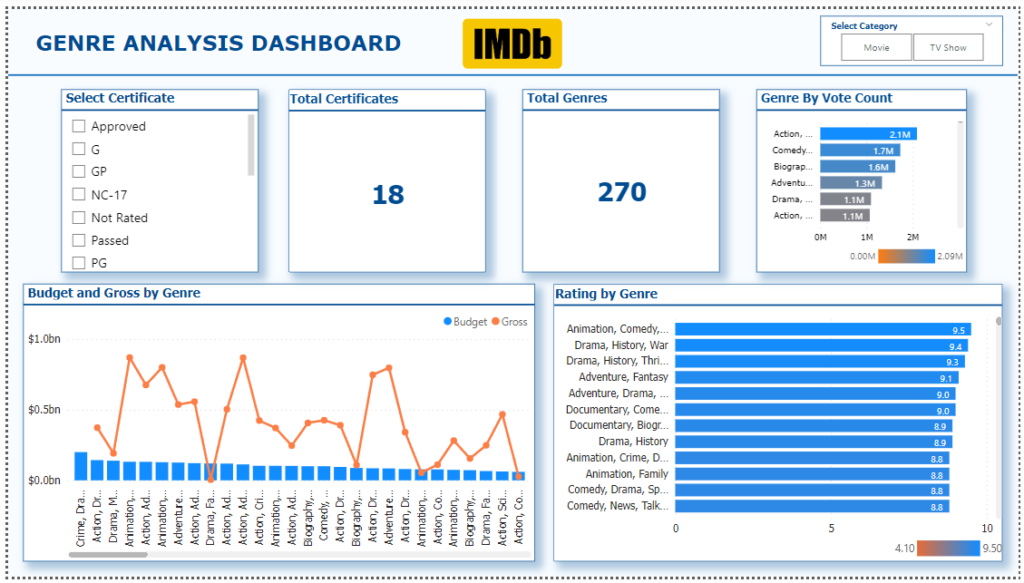
4. Genre Analysis Dashboard
- Visuals:
- Card Visual: Shows the total distinct count of Certificates.
- Card Visual: Shows the total distinct count of Genres.
- Bar Chart: Displays the average IMDb rating grouped by Genre, showing how different genres perform in terms of ratings.
- Bar Chart: Displays the average number of votes per genre.
- Bar and Line Chart: Plots the average Budget and Gross Revenue by genre, offering insights into which genres are more profitable.
- Slicers: Users can filter by Type (Movie or TV Show) and by Certificate (e.g., PG, R) to further explore the data.
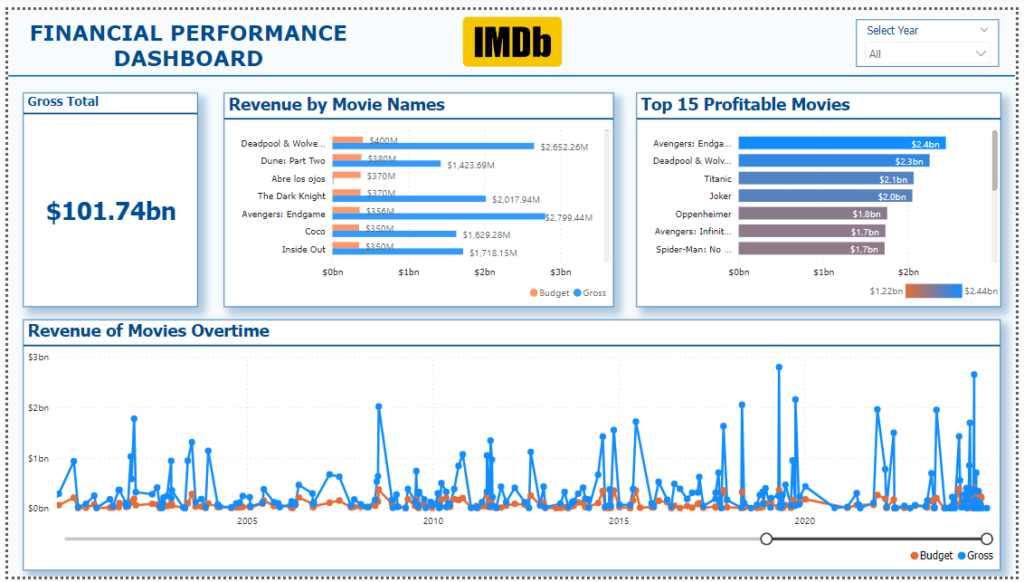
5. Financial Performance Dashboard
- Visuals:
- Card Visual: Shows the sum of the total gross revenue generated by all content in the dataset.
- Stacked Bar Chart: Compares the Total Budget Gross Revenueby movie, highlighting financial performance.
- Bar Chart: Displays the Top 15 most profitable movies, calculated as Gross Revenue minus Budget.
- Line Chart: Shows trends in Budgetand Gross Revenue over time, providing insights into how these figures have changed.
- Slicer: Allows filtering by year to focus on the gross revenue generated in specific years.
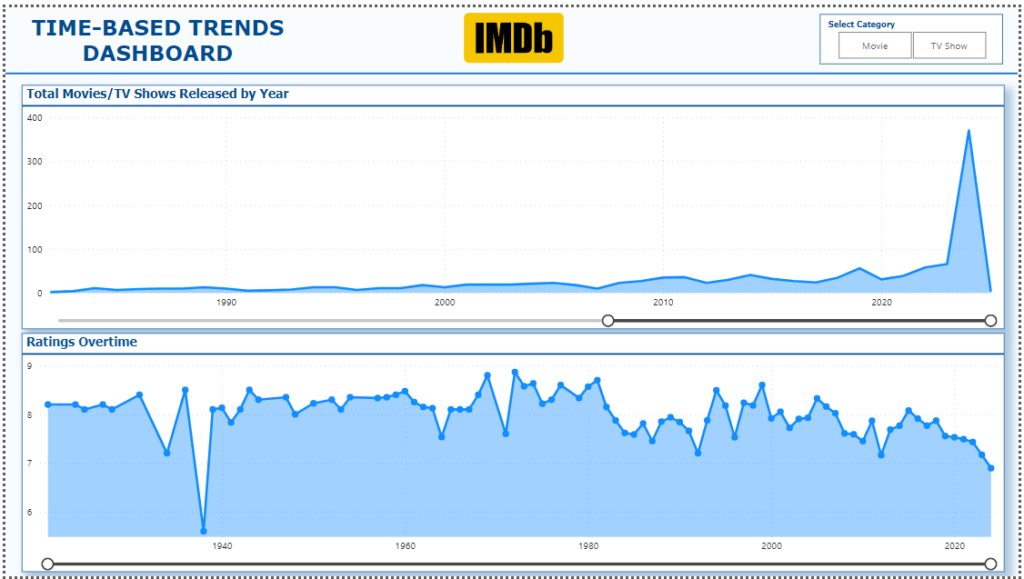
6. Time-Based Trends Dashboard
- Visuals:
- Line Chart: Shows the number of movies and TV shows released each year, offering a view of how releases have trended over time.
- Line Chart: Tracks IMDb ratings over time, providing insight into how ratings have fluctuated.
- Slicer: Filters the data by Type(Movie or TV Show) to allow for analysis of time-based trends for either category.
These dashboards provide both a high-level overview and deeper insights into the performance, ratings, and financial success of movies and TV shows from IMDb data.
To get code files and Dashboards, visit the following link:
https://github.com/furqanuppal/IMDB/


